Overview¶
This section of the documentation details Grove internals. This documentation is intended for users who wish to extend Grove, or users who are curious about how Grove works.
Flow¶
A rough diagram of the overall flow of a Grove run (“collection”) can be found below.
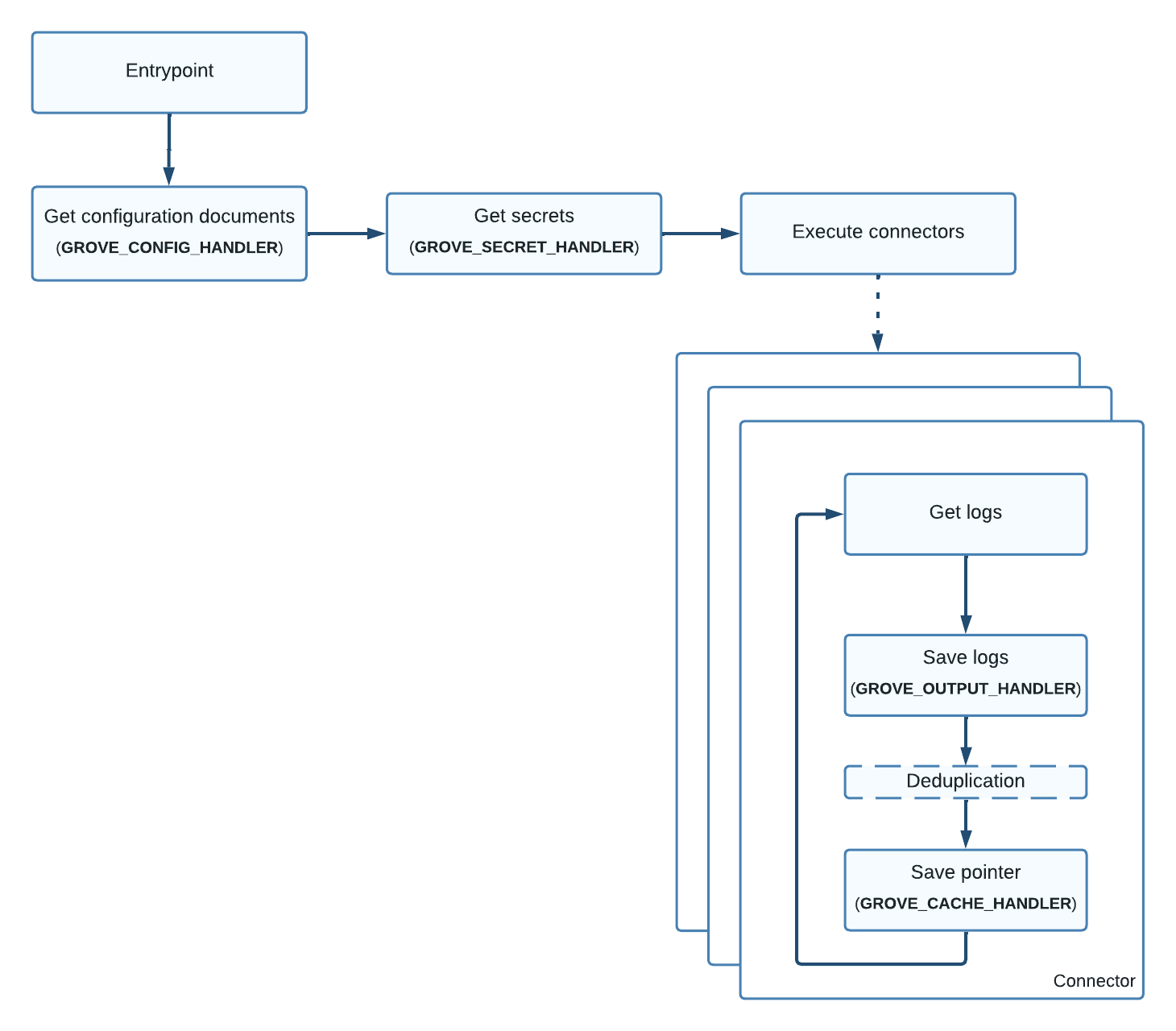
Components¶
Grove is designed to be modular. This modularity allows users to pick from a series of available plugins and connectors which best fit their environment, rather than requiring a user to deploy a specific set of products.
As an example, a user deploying Grove into AWS may want to use native AWS services for configuration, caching, and log storage. However, an on-premises user may instead want to keep everything local to their data centres using locally deployed services.
The two main types of components in Grove are Plugins and Connectors.
Plugins¶
Plugins tell Grove how to fetch connector configuration, where Grove should put collected logs, how Grove should remember which logs have already been collected, and where Grove can get secrets from.
Effectively, a Grove plugin implements support for a backend of a particular type.
An example of a Grove plugin is grove.outputs.aws_s3. This output plugin tells
Grove how to write collected logs to AWS’ S3 service.
Structure¶
To ensure consistency, and to reduce the amount of code that a developer needs to write to extend Grove, several base classes are defined which represent the different sorts of backends that Grove can talk to.
For cache backends,
grove.caches.BaseCacheis used.For configuration backends,
grove.configs.BaseConfigis used.For output backends,
grove.outputs.BaseOutputis used.For secrets backends,
grove.secrets.BaseSecretis used.
These classes abstract away important operations which allow Grove to keep track of its place (”Caches”), fetch configuration documents (”Configs”), output logs (”Outputs”), and fetch credentials (”Secrets”).
A visual overview of the relationship between built-in Grove backends and their base classes can be found below. Although the examples in this image are built-in to Grove, they follow the same principals as any other Plugin.
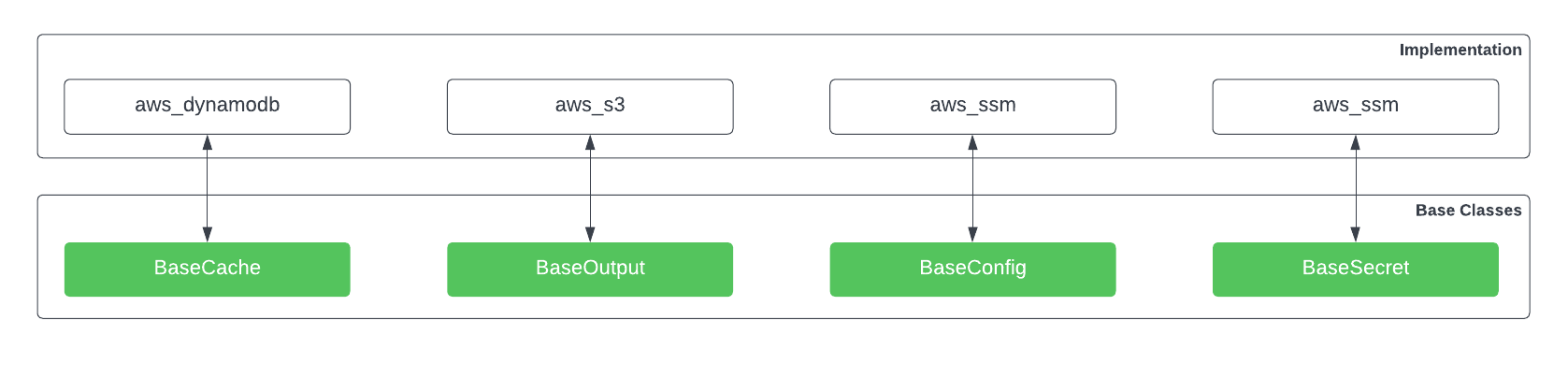
Configuration¶
The plugins Grove should use, and the configuration for each of these plugin, is defined using environment variables.
Environment variables are used to allow Grove to be configured in the same manner whether deployed as a service on a Linux machine, a serverless function, or scheduled into a container environment.
The environment variables that control which Grove plugins should be used are as follows:
GROVE_OUTPUT_HANDLER(Default:local_stdout)GROVE_CONFIG_HANDLER(Default:local_file)GROVE_CACHE_HANDLER(Default:local_memory)GROVE_SECRET_HANDLER(Default: None)
Note
Each plugin will almost certainly define a set of configuration which must be set to be used. Please consult the documentation for the configured Grove plugins to understand what additional configuration is required.
Connectors¶
Connectors, tell Grove how to talk to particular application or service to collect logs. Connectors are the main units of work executed by Grove, as each connector is executed in an independent thread to allow collections to happen in parallel, and prevent an issue with one application or service from affecting others.
An example of a Grove connector is grove.connectors.github. This connector tells
Grove how talk to Github to collect logs from the Github audit events API.
Structure¶
Similar to plugins, connectors also must inherit from a base class. In this case, only
one class is available: grove.connectors.BaseConnector. This class does a
significant amount of lifting in the background, in order to ensure consistency between
connectors.
Configuration¶
Connector configuration, including which connectors Grove will use, is defined using configuration documents. These documents are retrieved from the configuration backend when Grove runs.
Please see the Configuration section of the documentation for more information.
Entrypoints¶
Warning
Grove Entrypoints are not the same as Setuptools Entrypoints!
Grove entrypoints are used to define how Grove is called by a run-time - such as Nomad.
Entrypoints extract run-time and deployment specific information such as unique
execution identifiers prior to calling grove.entrypoints.base.entrypoint to
start Grove.
This extracted information is referred to as context. This context is
automatically added to all logs collected by Grove to allow a user to pin-point a
collected log with when and how it was collected.
Note
Custom entrypoints are a great place for for users to setup their preferred observability tooling. Leave no unhandled exception untraced, and no collection failure unexplainable!
Discovery¶
In order to allow users to build and distribute their own plugins and connectors, Setuptools Entrypoints are used by Grove to discover installed plugins and connectors.
This allows users to build their own plugins and connectors to support applications and services not already supported by Grove. It also allows users to customise their deployment, installing connectors and plugins relevant to their environment.
As an example, a third-party developer wanting to create a new output plugin called
local_thing would “register” this plugin by adding the following code to
setup.py in their project.
setup(
entry_points={
"grove.outputs": [
"local_thing = grove_outputs_local_thing.local_thing:Handler",
],
}
)
In this example, the developer has created a new output handler
grove-outputs-local-thing. This project contains a local_http.py that
implements the logic to provide the “thing” output handler.
The actual implementation of the Handler, would appear something like the
following:
# File: grove_outputs_local_thing/local_thing.py
from grove.outputs import BaseOutput
class Handler(BaseOutput):
# ... implementation here ...
If desired, this third-party developer could then publish this new plugin in PyPI,
allowing other Grove users to install this plugin via pip. Once installed,
users can then use this plugin by setting the GROVE_OUTPUT_HANDLER environment
variable to the name of the plugin that the plugin was “registered” with by the
third-party developer (local_thing).
Note
This is a simplified overview of the creation of a new Grove plugin. For more information, please see the Development section of this documentation.
Pointers¶
As data is retrieved from an application or service application, a pointer is recorded by Grove in order to ensure that the relevant data is only collected once. These pointers are stored in the configured cache backend.
Warning
Grove preferences duplicate log entries over missed log entries!
As a result, duplicate data may occur where the upstream service uses inclusive range filtering. This is in order to prevent having to cache an identifier for every record ever seen, which would be expensive.
As an example, Slack’s Audit API uses a unix timestamp to as a way to filter which audit events should be returned. If and all known log entries were collected, the timestamp of the last record collected fetched would be stored in the cache, and considered the pointer.
If no existing pointer is in the cache, the connector will provide an initial value which is appropriate for the application. When Grove next runs, only log entries generated since / after this pointer would be collected.
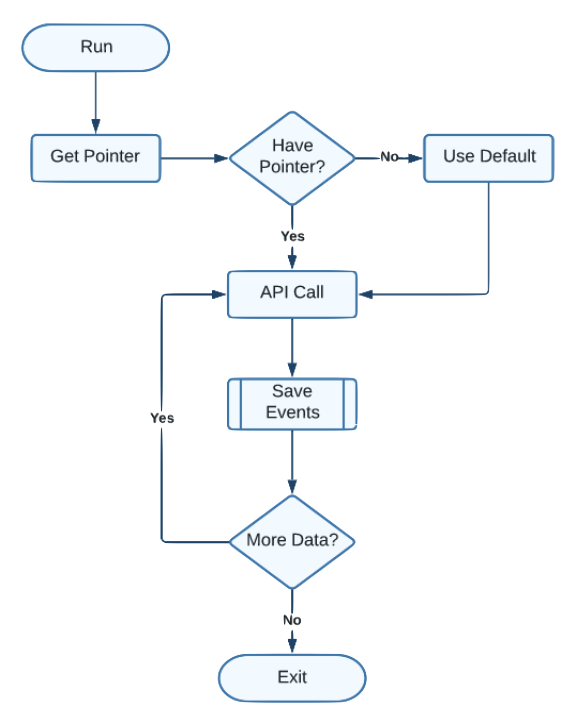
Cache¶
The Grove cache is used to track pointers and other volatile information which is used to keep track of where a Grove collection is up to. In order to make this as flexible as possible, the structure of this cache can be found below.
Although the terms “partition key” and “sort key” are used in this documentation, these three components can be used by a cache plugin to construct an appropriate object which adheres to best practices recommended for a given backend.
“Partition Key”¶
Field: pk (String)
This is a combination of the name of the data type, such as pointer, the
connector type, such as slack_audit, and a unique identifier associated with the
account the logs were collected from (hashed with MD5).
Hashing of the identity is required to constrain length and ensure compatibility certain product’s restrictive character set for “partition keys”. The unique account identifier is required to support multiple tenants in applications or services where this is required.
As an example, when using the grove.caches.aws_dynamodb backend the pointer for
the slack_audit connector used to collect data from slack enterprise
EC0FFEE1 would have a pk of
pointer.slack_audit.c3a087b5a3b197bc012233bef9062b18.
“Sort Key”¶
Field: sk (String)
This value should be the type of operation, or API, which the pointer is for. As an
example, the Slack Audit API has close to 200 different “actions” which can be queried
for. In order to ensure the correct pointer for each action type is recorded separate
entries would exist for actions workspace_created and workspace_deleted.
“Data”¶
Field: data (String)
This is the identifier or value used by the application or service to filter the range of the requested data. This may be a timestamp of the latest record, or a “next token” returned by the queried API.
Keeping with the Slack example, this would be a unix timestamp value of the last record
collected (such as 1607425434).
Example¶
An example of what data in AWS’ DyanmoDB would look like in this model has been included below for completeness:
pk |
sk |
data |
|---|---|---|
pointer.slack_audit.c3a087b5a3b197bc012233bef9062b18 |
workspace_created |
1607425434 |
pointer.slack_audit.c3a087b5a3b197bc012233bef9062b18 |
workspace_deleted |
1607421111 |
pointer.slack_audit.c3a087b5a3b197bc012233bef9062b18 |
emoji_added |
1607423333 |
Output¶
Grove is designed to allow support for outputting collected logs to arbitrary locations. While some users may want collected logs to be written directly to a local filesystem, others may want to write logs to AWS’ S3, or perhaps sent over HTTP to an external service.
In order to support these use cases, Grove allows the user to define an “output handler” to use when outputting collected logs.
This handler handler may be built into Grove, or defined by a third-party plugin. Additionally, if no suitable existing output handlers exist for a use case, custom plugins can be written to output collected logs in the way required.
Format¶
Note
Third-party output plugins may not output logs in this same format! This format has been used to simplify ingestion and processing by systems which consume Grove output.
The preferred and default output format for collected logs is Gzipped NDJSON (new-line delimited JSON). Log entries from a given collection are written to the same file, with each entry separated by new-line characters.
An example of an NDJSON file output by Grove, after decompression, can be found below:
{"id": "0001", "name": "Example One", "_grove": {}}
{"id": "0002", "name": "Example One", "_grove": {}}
{"id": "0003", "name": "Example One", "_grove": {}}
{"id": "0003", "name": "Example Two", "_grove": {}}